10.10.2016Projektende
Mit dem Projektende von dlexDB übernimmt die Berlin-Brandenburgische Akademie der Wissenschaften die Pflege von Webseite und Datenbank. Wir arbeiten im Moment mit Hochdruck an einer Überführung der Daten in die Infrastruktur von www.dwds.de. Dort werden Sie dann auch die Erweiterungen und Aktualisierungen des Datenbestandes recherchieren können. Wir werden Sie an dieser Stelle über die Entwicklungen informieren.
03.05.2013Neu: dlexDB-JSON-API
Seit heute bietet dlexDB eine Programmierschnitttelle zu seinen Tabellen an. Die Schnittstelle ist als RESTful Webservice implementiert und liefert die Ergebnisse im verbreiteten JSON-Format aus.
Beispiel (Filterabfrage): Eher seltene Types mit einem hochfrequenten Präfix (erste 3 Buchstaben), Sortierung nach Frequenz absteigend, erste 20 Ergebnisse:
Weitere Informationen auf unserer API-Überblicksseite.
06.09.2012Workshop 2011: Proceedings veröffentlicht


Die Proceedings zu unserem Workshop 2011 sind in der Reihe Potsdam Cognitive Science Series erschienen (Band 3). Der Band enthält folgende Beiträge:
- R. Harald Baayen
- Resource requirements for neo-generative modeling in (psycho)linguistics
- Lara Kresse, Stefan Kirschner, Stefanie Dipper, Eva Belke
- Towards exploring the specific influences of wordform frequency, lemma frequency and OLD20 on visual word recognition and reading aloud
- Emmanuel Keuleers, Marc Brysbaert, Boris New
- An evaluation of the Google Books ngrams for psycholinguistic research
- Julian Heister, Reinhold Kliegl
- Comparing word frequencies from different German text corpora
- Heike Zinsmeister, Eva Smolka
- Corpus-based evidence for approximating semantic transparency of complex verbs
- Benny B. Briesemeister, Markus J. Hofmann, Lars Kuchinke, Arthur M. Jacobs
- The BAWL databases in research on emotional word processing
22.06.2012Neue Tabellen, alle Maße auch schreibungsnormalisiert
Die neue Version 0.3 von dlexDB bringt zehn neue Tabellen. Zum einen haben wir von allen vorhandenen Tabellen jeweils ein schreibungsnormalisiertes Abbild erstellt (wo anwendbar):
| Tabelle (Original) | Tabelle (schreibungsnormalisiert) |
|---|---|
| Types | Types DC |
| Zeichen | Zeichen DC |
| Zeichenbigramme | Zeichenbigramme DC |
| Zeichentrigramme | Zeichentrigramme DC |
| Nachbarn Coltheart | Nachbarn Coltheart DC |
| Nachbarn Levenshtein | Nachbarn Levenshtein DC |
In den schreibungsnormalisierten Tabellen sind jeweils mehrere Groß-/Kleinschreibungsvarianten eines Types in einer kleingeschriebenen Repräsentation zusammengefasst. Diese Repräsentation ist künstlich und kommt oft selbst nicht im Korpus vor. Zu diesen kleingeschriebenen Repräsentationen finden Sie alle Maße, die Sie auch in den bereits vorhandenen Tabellen finden, jedoch in einer Variante, die ohne Berücksichtigung von Groß-/Kleinschreibung berechnet wurde. Sie erhalten also z.B. Frequenzen oder Nachbarschaftsmaße auch jetzt auch in einer case-insensitive-Variante.
Darüber hinaus gibt es jetzt sowohl von den rein orthographisch definierten Types als auch von den neu erstellten schreibungsnormalisierten Types Bi- und Trigramme. Die Bi- und Trigramme aus annotierten Types, die noch differenziertere Frequenzabfragen ermöglichen, bleiben zusätzlich erhalten:
| Annotierte Types | Types (Original) | Types (schreibungsnormalisiert) | |
|---|---|---|---|
| Bigramme | Annotierte Typebigramme | Typebigramme | Typebigramme DC |
| Trigramme | Annotierte Typetrigramme | Typetrigramme | Typetrigramme DC |
Desweiteren gibt es eine funktionale Neuerung: Von nun an ist die Listensuche in allen Tabellen möglich. Sie können beispielsweise eigene Typebigramme oder -trigramme hochladen und gegen dlexDB abgleichen.
Schließlich haben wir auch die Benutzerdokumentation überarbeitet und erweitert. Wir hoffen, auf diese Weise Ihren Fragen besser gerecht werden zu können und freuen uns schon darauf, bald weitere inhaltliche und funktionale Verbesserungen vorstellen zu dürfen.
Links zu den wichtigsten Neuerungen:
13.11.2011Zweite Förderperiode
dlexDB geht in die zweite Periode seiner Förderung durch die DFG. Momentan bereiten wir die Veröffentlichung neuer Daten und Updates vor.
18.09.2011Steigende Benutzerzahl
Wir freuen uns, dass dlexDB im dritten Jahr seiner Entwicklung immer mehr Benutzer findet. Die Anzahl der ausgeführten Datenbankabfragen stieg zuletzt auf über 3000 pro Monat. Bitte senden Sie uns weiterhin Ihre Fragen, Anregungen oder Kritik über das Kontaktformular.
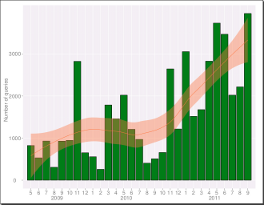
Vergrößern
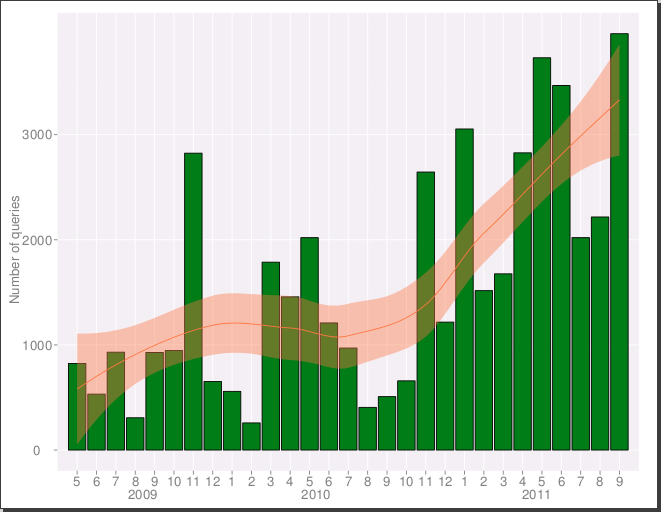
13.09.2011Download/Export: Ausführliche Spaltennamen
Angemeldete Benutzer haben die Möglichkeit, die ersten 10.000 Treffer einer Abfrage herunterzuladen. Die resultierende CSV-Datei enthält in der ersten Zeile die Spaltennamen. Bisher wurden hier die internen Spaltenbezeichnungen aus unserer Datenbank-Abstraktionsschicht angegeben. Ab sofort werden hier die ausführlichen natürlichsprachlichen Spaltenbezeichnungen eingesetzt, wie sie auch auf der Website in der Ergebnistabelle verwendet werden. Alle in dlexDB enthaltenen Variablen sind hier dokumentiert.
01.07.2011Neue Variablen: Wortbigramme und Worttrigramme: Bedingte Wahrscheinlichkeit; Orthographische Frequenzen
Mit Version 0.2.3 hatten wir bereits die Durchschn. bed. Wahrsch., bigrammbasiert von Types in dlexDB aufgenommen. Ergänzend dazu veröffentlichen wir nun auch die zugrundeliegenden Einzelwerte, d.h. die bedingten Wahrscheinlichkeiten von Wortbigrammen, gegeben die erste Komponente, und von Worttrigrammen, gegeben das initiale Wortpaar.
In diesem Zusammenhang geben wir von nun an für Annotierte Typebigramme und Annotierte Typetrigramme auch rein orthographisch basierte Frequenzen" an. Update: Rein orthographisch basierte Frequenzen finden Sie jetzt in den neuen Tabellen Typebigramme und Typetrigramme. Bislang enthielten diese beiden Tabellen nur die Frequenzen separat nach den oft mehreren morphosyntaktischen Analysen (annotierte Frequenzen). Bei dieser Gelegenheit haben wir den Zugang zu den beiden Tabellen behutsam verändert: Es ist nun möglich, Wortbigramme oder Worttrigramme in einem einzigen Eingabefeld einzugeben, die einzelnen Komponenten durch Leerzeichen getrennt. In der Voreinstellung wird nur noch dieses Eingabefeld angezeigt.
Aktuelle dlexDB-Version: 0.2.5
01.06.2011Update: Familiarität, Regularität und Wortanfangsfrequenzen korrigiert
In der Types-Tabelle wurden die Spalten Familiarität, Regularität, Initiales Zeichen, Initiales Zeichenbigramm und Initiales Zeichentrigramm aktualisiert. In der vorhergehenden Version von dlexDB wurden hier für einige Types, insbesondere für solche mit Umlauten, falsche Werte angegeben.
Bitte richten Sie sich darauf ein, dass aber auch diese neuen Werte sich im Zuge der Elimination von Fehlerkennungen und Korpusartefakten nochmals geringfügig ändern werden.
Aktuelle dlexDB-Version: 0.2.4
04.04.2011Bedingte Wahrscheinlichkeit und Informationsgehalt von Types
Die Types-Tabelle wurde um die Spalten Durchschn. bed. Wahrsch., bigrammbasiert und Durchschn. Inf.-Geh., bigrammbasiert ergänzt. Der durchschnittliche Informationsgehalt eines Types ist ein Maß, das aktuell in einer Arbeit von Piantadosi et al., 2011 diskutiert wird. Piantadosi et al. zeigen, dass der durchschnittliche Informationsgehalt eines Types ein stärkerer Prädiktor für die Typelänge ist als die Frequenz des Types. Die Autoren sehen darin eine Revision oder Verbesserung des sogenannten Gesetzes von Zipf, 1936, der als erster einen Zusammenhang zwischen Typelänge und Typefrequenz postuliert hatte.
Piantadosi et al. haben als Korpusbasis die sogenannten Google-5-Gramme (Web) benutzt, ein umfangreiches Korpus von Webinhalten in zehn europäischen Sprachen, darunter das Deutsche. dlexDB hat die von den Autoren benutzten Maße auf der Basis unseres Referenzkorpus DWDS nachberechnet und erlaubt es somit allen Interessierten, die von Piantadosi et al. beobachtete Korrelation auf der Basis eines aus gedruckten Texten zusammengesetzten, ausgewogenen Korpus des 20. Jh. zu überprüfen.
Aktuelle dlexDB-Version: 0.2.3
31.03.2011dlexDB-Workshop archiviert; dlexDB-Überblicksartikel erschienen
Am 28. März 2011 organisierte das dlexDB-Projekt in Verbindung mit der QITL-4-Konferenz „Quantitative Investigations in Theoretical Linguistics“ einen Workshop zum Thema „Lexical Resources in Psycholinguistic Research“. Das Programm des Workshops wurde auf dieser Seite archiviert. Sie finden dort erweiterte Abstracts zu den Vorträgen (die vollständigen Proceedings werden in Kürze nachgereicht).
Weitere Publikationen von und in Verbindung mit dlexDB finden Sie auf der Seite Publikationen. In Ausgabe 1/2011 der „Psychologischen Rundschau“ haben wir dlexDB in einem Überblicksartikel vorgestellt.
18.01.2011dlexDB-Workshop: Deadline extended
Please note that the deadline for submissions regarding our workshop in March has been extended until Monday, Jan 31, 2011. For further details, please see the announcement below.
28.12.2010Neue Tabellen: Nachbarn Coltheart, Nachbarn Levenshtein
Mit der neuen dlexDB-Version 0.2.2 werden die neuen Tabellen Nachbarn Coltheart und Nachbarn Levenshtein freigegeben. Darin finden Sie zu jedem Type aus Types alle orthographischen Nachbarn (Editierabstand 1), einmal nach der Definition von Coltheart et al. (1977), und einmal nach der Definition von Levenshtein (1966). Die Anzahl der orthographischen Nachbarn und ihre aufsummierte Frequenz finden Sie weiterhin in der Tabelle Types.
Desweiteren wird von nun an für alle Frequenzen und Zählungen neben dem absoluten Wert, dem normalisierten und logarithmierten Wert auch der Frequenzrang (in zwei Varianten) angegeben.
23.11.2010Workshop Lexical Resources in Psycholinguistic Research 28.03.2011
Experimental and quantitative research in the field of human language processing and production strongly depends on the quality of the underlying language material: beside its size, representativeness, variety and balance have been discussed as important factors which influence design, analysis and interpretation of experiments and their results. The workshop aims to bring together creators and users of both general purpose and specialized lexical resources which are used in psychology, psycholinguistics, neurolinguistics and cognitive research. It will be a forum to report experiences and results, review problems and discuss perspectives of any linguistic data used in the field.
Invited speaker: R. Harald Baayen, University of Alberta, Canada
Call for Participation
We invite researchers to contribute by submitting abstracts for 30 minutes talks with additional 10 minutes for discussion. The abstracts should reflect your work on or with lexical resources in the aforementioned research areas and should not exceed 1000 words (excluding figures, tables and references). Please send your submissions to info@dlexdb.de electronically until the Jan 15, 2011 Jan 31, 2011. Each abstract will be reviewed by at least two members of the review board.
QITL-4
The workshop “Lexical Resources in Psycholinguistic Research” takes place on 28th of March 2011 at the 4-th Conference on Quantitative Investigations in Theoretical Linguistics (QITL-4). Details will soon be available on the website.
Workshop organizers: Reinhold Kliegl (University of Potsdam) · Alexander Geyken (BBAW) · Julian Heister (University of Potsdam) · Edmund Pohl (BBAW) · Kay-Michael Würzner (University of Potsdam) · Review Board: Olaf Dimigen (Humboldt University Berlin) · Bryan Jurish (BBAW) Emmanuel Keuleers (Ghent University) · Wolfgang Klein (MPI for Psycholinguistics Nijmegen) · Astrid Schröder (University of Potsdam) · Shravan Vasishth (University of Potsdam) · Christiane Wotschack (Free University Berlin)
02.08.2010Speichern und Wiederaufrufen von Abfragen
Ab sofort können Sie als angemeldete/r Benutzer/in beliebige Abfragen in Ihrem Benutzerprofil speichern und diese später wieder aufrufen. Zu jeder gespeicherten Abfrage erhalten Sie eine Kurz-URL, die Sie als Lesezeichen speichern oder z.B. per Email verschicken können (Sie können Abfragen als privat oder öffentlich deklarieren).
Ein Beispiel für eine öffentliche gespeicherte Abfrage finden Sie hier: http://dlexdb.de/Qgmilhc
Weitere Informationen in der Dokumentation: Abfrage speichern
Direkt zum Abfrageformular: dlexDB-Abfrage
12.06.2010Neue Tabellen: Zeichen, Zeichenbigramme, Zeichentrigramme
Mit der neuen dlexDB-Version 0.2.1 werden die sublexikalischen Tabellen Zeichen, Zeichenbigramme und Zeichentrigramme freigegeben. Sie enthalten alle in den Types vorkommenden Zeichen, Zeichenbigramme bzw. Zeichentrigramme. Zu jeder Einheit wird sowohl ihre Tokenfrequenz (Auftretenshäufigkeit im Korpus) als auch ihre Typefrequenz (Auftretenshäufigkeit in der Liste der Types) angegeben.
Auf Grundlage der neuen sublexikalischen Daten wird die Types-Tabelle um sechs Spalten erweitert. Zu jedem Type werden die kumulierten Frequenzen der enthaltenen Zeichen, Zeichenbigramme und Zeichentrigramme angegeben.
Analog zu den kumulierten Zeichenfrequenzen wird in der Types-Tabelle nun auch die kumulierte Silbenfrequenz bereitgestellt.
Schließlich bietet die Types-Tabelle von nun an als neue Maße einerseits den in der Literatur etablierten Punkt der orthographischen Eindeutigkeit (Uniqueness Point) an. Desweiteren wird als experimentelles Maß der Punkt der Lemma-Eindeutigkeit angegeben, d.h., ab dem wievielten Buchstaben einer Wortform ist das zugrundeliegende Lemma eindeutig bestimmt.
08.05.2010Neue Tabellen: Wortbigramme, Worttrigramme und Silben
Mit Version 0.2 wird dlexDB in Richtung der supralexikalischen Ebene (Mehrwortebene) erweitert: In den neuen Tabellen Annotierte Typebigramme und Annotierte Typetrigramme lassen sich Zwei- bzw. Dreiwortverbindungen und ihre Auftretenshäufigkeiten abfragen.
Gleichzeitig findet auch eine Erweiterung auf sublexikalischer Ebene statt: Die Silben-Tabelle listet alle in dlexDB-Types vorkommenden Silben. Zu jeder Silbe wird sowohl ihre Tokenfrequenz (Auftretenshäufigkeit im Korpus) als auch ihre Typefrequenz (Auftretenshäufigkeit in der Liste der Types) angegeben.
Die Benutzeroberfläche wurde erweitert und übersichtlicher gestaltet: Die Tabellenauswahl befindet sich nun in der oberen rechten Ecke des Arbeitsbereiches, und alle für die jeweilige Tabelle verfügbaren Filter- bzw. Ausgabeoptionen sind über eine hierarchisch gegliederte Baumstruktur (am rechten Fensterrand) erreichbar.
05.08.2009Öffentliche Betaversion
Das dlex-Projekt veröffentlicht die erste Betaversion von dlexDB mit der Versionsnummer 0.1. Zunächst werden folgende drei Tabellen bereitgestellt: Die Types-Tabelle enthält alle im zugrundeliegenden Korpus vorkommenden Types (ca. 2,3 Mio.). Die Annotierte Types-Tabelle enthält alle annotierten Types (ca. 2,7 Mio.): zwei annotierte Types können orthographisch identisch sein, müssen sich dann aber hinsichtlich der ihnen zugeordneten Part-of-Speech-Tags unterscheiden (d.h., sie müssen unterschiedliche morphosyntaktische Analysen haben). Die Lemmata-Tabelle enthält alle ca. 1,8 Mio. zugrundeliegenden Lemmata.
Neben den Frequenzen wird eine erste Auswahl an für die psycholinguistische Forschung relevanten Variablen zur Abfrage angeboten. Dazu zählen: Familiarität, Regularität, Frequenz des initialen Zeichenbigramms und verschiedene Nachbarschaftsmaße (Wortähnlichkeit). Eine detaillierte Beschreibung aller dlexDB-Variablen finden Sie in der Dokumentation.
Aktuelle Version
- 0.3
- Neue Tabellen: alle Maße auch schreibungsunabhängig verfügbar
Workshop 2011
Die Proceedings zu unserem Workshop Lexical Resources in Psycholinguistic Research (März 2011) sind in der Potsdam Cognitive Science Series erschienen. Workshop-Seite

